1. 패킹 개요
1.1. 패킹(Packing) 개념과 난독화된 악성코드
오늘은 공부했던 내용 중 꽤 흥미로웠던 패킹과 엔트로피에 대해 정리를 해보고자 한다. 먼저 패킹의 개념에 대해서 설명을 해야 한다.
windows의 실행파일(PE 파일)에 대한 이해가 필요하지만 해당 게시물에서 PE파일에 대한 내용을 같이 정리하기보단 따로 정리하는 게 좋을 거 같아 해당 게시물에선 건너뛰고 정리하도록 한다.
먼저 패킹(Packing)이란? 실행 파일(PE 파일)의 내부 코드를 압축하거나 암호화하여 파일의 형태를 포장하는 기술을 말한다.
쉽게 말해 실행 파일의 분석을 어렵게 하기 위해 코드를 압축하거나 암호화하는 것이다.
악성코드 제작자는 파일의 탐지와 분석을 더 어렵게 할 목적으로 패킹과 난독화 기법을 사용한다.
난독화된 프로그램은 악성코드 제작자가 은폐를 시도한 실행코드이고 패킹된 프로그램은 악성코드 프로그램이 압축돼 분석할 수 없게 난독화된 프로그램의 일부이다.
두 기법 모두 악성코드를 정적으로 분석하려는 시도를 어렵게 만드는 것이다.

패킹에 대한 개념을 직관적으로 이해할 수 있도록 아주 간단하게 그림으로 표현해보았다.
그림에 보이다시피 패킹되거나 난독화된 악성코드는 문자열이 거의 없다.
이 말은 즉 Strings로 검색했을 때 문자열이 검색되지 않거나 소수의 문자열만 보인다면 난독화됐거나 패킹된 악성코드일 가능성이 있다는 것을 암시할 수 있다.
암호화시키거나 패킹시키는 프로그램을 wrapper라고 한다.
패킹된 프로그램을 실행하게 되면 작은 wrapper 프로그램이 패킹된 파일의 압축을 해제한 후 언패킹된 파일을 실행한다.
패킹된 프로그램을 정적으로 분석할 때는 작은 래퍼 프로그램만 분석할 수 있다.

1.2. 공격자들이 패킹을 사용하는 이유
패킹된 프로그램은 위에 첨부한 사진과 같이 원본 실행 파일에 비해 대부분의 정보가 압축되어 가시적인 정보를 확인하기 어렵다.
따라서 악성코드 제작자 혹은 공격자들은 자신이 만든 악성코드가 쉽게 탐지되거나 분석되는 것을 막기 위해 패킹을 적극적으로 악용한다.
- 정적 분석 우회: 안티바이러스(백신) 도구는 파일 내부의 특정 문자열이나 코드 패턴(시그니처)을 보고 악성 여부를 판단한다. 패킹을 하면 원본 코드가 완전히 뭉개지거나 암호화되므로 정적 시그니처 탐지를 우회할 수 있다.
- 리버싱 방지 및 분석 지연: 분석가가 OllyDbg, x64dbg 같은 디버거나 IDA 같은 디스어셈블러로 파일을 열었을 때 원본 코드 대신 복잡한 언패킹 루틴만 보이게 만들어 분석을 까다롭게 하고 대응 시간을 늦출 수 있다.
정리하면 공격자들이 패킹을 쓰는 핵심 이유는 이 두가지로 요약할 수 있다.
패킹된 파일을 탐지하는 방법도 여러 가지가 있지만 이 역시 해당 게시물의 주요 토픽이 아니기 때문에 다른 게시물에 따로 정리를 하도록 할 것이다.
2. 엔트로피(Entropy)
2.1. 엔트로피(Entropy) 개념
패킹의 개념에 대해 이해했으니 이제 엔트로피에 대한 개념이다.
열역학에서의 엔트로피의 개념은 물질과 에너지가 질서 있는 상태에서 무질서한 상태로 이동하는 정도를 나타내는 물리량이라고 설명할 수 있다.
정보 이론에서의 엔트로피도 위의 틀을 크게 벗어나지 않는다.
엔트로피(Entropy)는 데이터의 '불확실성' 또는 '무작위성(Randomness)'을 정량적으로 나타낸 수치이다.
파일 분석 관점에서의 엔트로피는 특정 파일 내에 데이터(바이트 값)가 얼마나 고르게 무작위로 분포해 있는지를 의미한다.

이 엔트로피 개념은 파일의 소스코드를 직접 열어보지 않고도 정적 분석 단계에서 패킹 유무를 높은 확률로 찍어낼 수 있는 강력한 무기가 된다.
간단히 먼저 설명하면 엔트로피는 불확실성, 무작위성을 정량적으로 나타낸 수치이다.
위에서 그림으로 표현했던 일반 실행파일과 패킹된 실행파일을 비교해 보면 일반 실행파일에 비해 패킹된 실행파일은 데이터가 '무작위'로 구성되어 있기 때문에 데이터가 불확실하다.
데이터가 불확실하다는 점은 엔트로피의 값이 크다는 점으로 이어지게 된다.
2.2. 엔트로피의 수학적 의미
수학적으로 파일의 엔트로피는 각 바이트(0x00 ~ 0xFF)가 나타날 확률을 기반으로 계산된다.
이 확률은 창시자인 클로드 섀넌(Claude Shannon)의 '섀넌 엔트로피(Shannon Entropy)' 공식을 기반으로 계산된다.
파일 내부의 각 바이트(0x00 - 0xFF, 총 256개 종류)가 나타날 확률을 기반으로 측정되며 공식은 다음과 같다.

여기서 P(xi)는 사건 xi가 발생할 확률을 의미한다.
이 수식에 따라 파일의 엔트로피는 최소 0에서 최대 8(log2(256)) 사이의 값으로 수렴하게 된다.
정리하자면
- 낮은 엔트로피 (0에 가까움): 데이터가 매우 예측 가능하고 일정 패턴이 반복되는 상태이다. 예를 들어 파일 내부가 0x00이나 0x90 (NOP) 같은 특정 데이터로 길게 채워져 있다면(데이터 패딩) 불확실성이 낮으므로 엔트로피가 떨어진다.
- 높은 엔트로피 (8에 가까움): 데이터가 규칙 없이 무작위로 흩어져 있어 다음 바이트에 어떤 값이 올지 전혀 예측할 수 없는 상태이다.
2.3. 일반 파일과 패킹된 파일의 헥사(Hex) 데이터 분포 차이
PE 포맷의 일반적인 파일은 엔트로피의 값이 낮은 편이다.
파일 전체에 저장된 값들 중에서 0x00(Null) 값이 훨씬 많기 때문에 일반적인 파일 내에서 어떤 값을 선택했을 때 0h 값이 선택될 확률이 매우 높고, 이것이 복잡성의 감소를 불러오기 때문에 결국 엔트로피의 값이 낮아지게 된다.
이에 반해 패킹된 PE 포맷 파일은 일반적인 파일에 비해 엔트로피의 값이 눈에 띄게 높다.
패킹하는 것은 압축하는 것이고 압축이라는 것은 파일 내에서 자주 보이는 패턴을 특정한 작은 값으로 변환하는 원리이다.
파일의 크기가 클수록 자주 보이는 패턴들이 더욱 많아진다.
따라서 자주 보이는 패턴들을 대체할 특정한 작은 값들이 많이 필요하게 된다.
압축되지 않은 파일에서는 자주 보이는 패턴으로 구성된 값들의 비중이 높다면 패킹된 파일은 0h부터 FFh까지 자주 사용되는 패턴을 대체할 임의의 작은 값들이 상대적으로 고르게 분포된다.
따라서 이것이 복잡성을 증가시키기 때문에 결국 엔트로피의 값이 높아지게 된다.
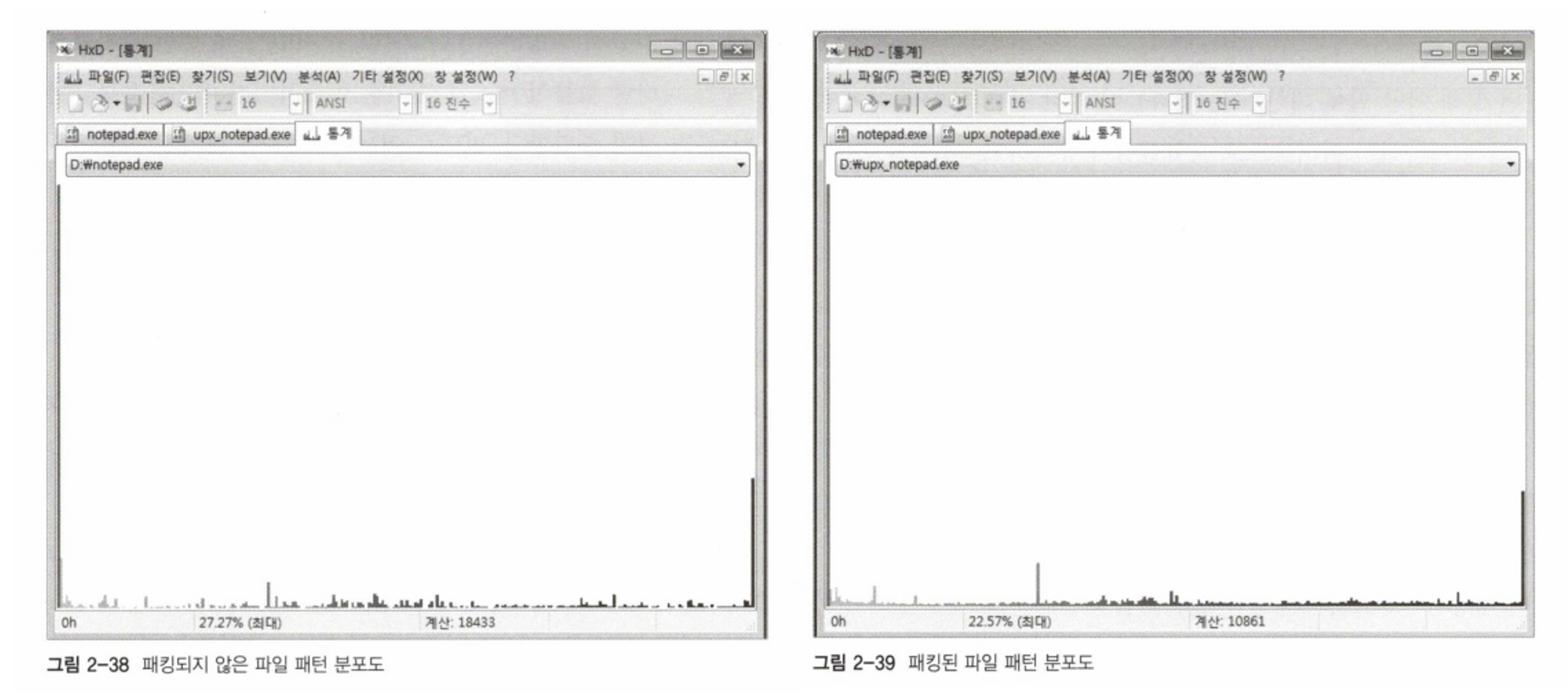
그림을 보면 패킹되지 않은 일반 파일을 구성하는 헥사 값들 중 0h 값이 18433개에서 패킹 후 10861개로 약 7800개 정도 감소했고 0h를 제외한 1h부터 FFh의 값들은 패킹하기 전에 비해 상대적으로 증가했음을 확인할 수 있다.
3. peframe.py와 엔트로피
3.1. peframe.py
패킹과 엔트로피의 개념에 대해서 이해했으면 이제 peframe.py를 통해 엔트로피 기준값에 따른 malware 판별법이 구체적으로 어떻게 이루어지는지를 확인할 것이다.
먼저 peframe.py는 python기반의 악성코드 분석 도구이고 exe 파일을 다양한 옵션을 통해 자동으로 분석한다. API 정보, 안티 디버그 정보, 악성코드 유무 등에 대한 전반적인 내용을 분석할 수 있는 오픈소스 도구이다.

peframe.py의 각 모듈별 자세한 분석 내용 역시 따로 게시물로 올릴 예정이다.
위의 사진과 같이 다양한 옵션을 제공한다.
오늘 게시물에선 peframe을 구성하는 함수들 중 SECTIONS 함수에 대해 간략히 이야기할 것이다.
3.2. SECTIONS 함수의 역할
peframe.py에서 실행 파일을 분석할 때 가장 중요하게 다뤄지는 모듈 중 하나가 바로 각 섹션(Section)의 정보를 파싱 하는 파트이다.
PE 파일은 코드(text), 데이터(data), 리소스(rsrc) 등 역할에 따라 섹션이 나뉘어 있는데 악성코드들은 주로 특정 섹션에 자신을 패킹해 두기 때문이다.
자세한 코드 설명은 생략하고 함수의 역할에 대해 간단하게 정리하면 SECTIONS 함수는 말 그대로 섹션의 정보를 확인할 수 있는 함수이다.
이 말은 즉, 섹션의 정보 = 의심스러운 섹션인지? = 악성코드 같은 섹션인지? 에 대해 확인을 할 수 있음을 의미한다.

sections 함수의 중요한 부분을 발췌했다. 의심스럽다는 말은 악성코드로 의심된다는 의미이다.
if함수 내의 2가지 조건을 통해 의심스러운 섹션인지 확인할 수 있다.
section.SizeOfRawData == 0 or ( 0 < section.get_entropy() < 1 or 7 < section.get_entropy() )
이 두 가지 조건 중 하나라도 만족한다면 peframe은 그 섹션을 의심스러운 섹션으로 분류한다.
3.3. 조건 1: section.SizeOfRawData == 0
section.SizeOfRawData는 파일에서 해당 섹션이 차지하는 공간을 나타낸다.
해당 값이 0일 경우 의심스러운 섹션으로 판단하게 된다.
섹션의 크기가 0이라는 것은 실제 파일상에서 사용되지 않는 공간이라는 의미이다. 하지만 섹션이 굳이 잡혀있다는 것은 메모리상에서 사용하기 위함이라고 볼 수 있다.
쉽게 이야기해서, 사용하기 위해 할당은 되어있지만 실제 파일상에선 사용되지 않는 공간인 것이다.
이것은 패킹된 파일의 전형적인 특징 중 하나이다.

그림을 보면 패킹된 파일 상태에서 UPX0섹션의 크기가 0이고 UPX1 섹션은 압축된 데이터들을 저장하고 있다.
언패킹 되는 과정(1 -> 2)을 거치고 나면 UPX1에 들어있던 압축된 데이터가 UPX0 안에 풀어지게 된다.
이때 비어있는 공간은 UPX1의 압축된 데이터를 재구성해 동작을 위해 사용하기 위해 비어있음을 의미한다.
특정 섹션을 파일에서는 사용하지 않지만 메모리상에서 사용한다는 것은(SizeOfRawData == 0) 이와 같이 실행 파일이 실행되기 위해 압축된 어떤 데이터가 쓰여지기 위해 할당되어 있는 섹션이라고 볼 수 있다.
이를 통해 패커가 메모리상에 올라간 패킹된 코드를 언팩 하면서 언팩 된 코드를 풀어낼 공간으로 활용하기 위해 만든 섹션임을 짐작할 수 있다.
이러한 논리를 통해 크기가 0인 섹션이 있다는 것은 분석 대상 파일이 패킹된 악성코드임을 의심할 수 있다.
3.4. 조건 2: 0 < section.get_entropy() < 1 or 7 < section.get_entropy()
두 번째 기준은 특정 섹션에 대한 엔트로피 값에 대한 내용이다.
위에서 서술했던 엔트로피의 개념이 해당 조건에서 적용되게 된다.
이 조건은 특정 섹션에 대한 엔트로피 값이 0 초과이거나 1 미만 일 경우, 또는 엔트로피 값이 7을 초과할 경우 해당 섹션을 의심스러운 섹션으로 판단한다.
의심스러운 섹션으로 분류되는 엔트로피에 대한 조건은 또다시 2가지로 나뉜다.
먼저, 엔트로피 값이 0일 경우이다. (1보다 작은 값으로 0으로 수렴)
이는 데이터가 텅 비어있다는 것을 의미하므로 비정상적인 섹션으로 분류되기 때문에 의심스러운 섹션이라고 판단한다.
정상적인 데이터 구조로는 어떠한 값이든 데이터가 채워져 있기 때문에 엔트로피 값이 0일 수가 없기 때문이다.
예를 들어 어떤 섹션의 크기가 10KB인데 그 안이 전부 0x00 (Null)이나 0x90 (NOP)으로만 꽉 채워져 있다면 엔트로피가 0이 나오게 된다. (모두 같은 값이기 때문에 불확실성이 0으로 수렴)
정상적인 프로그램이라면 CPU가 실행할 명령어(text), 문자열, 이미지 리소스 등 다양한 바이트가 섞여 있어서 아무리 낮아도 엔트로피가 4~6 수준을 유지하기 때문에 0이라는 의미는 공간은 차지하지만 데이터는 비어있다는 뜻이 된다.
비정상적인 데이터일 수 있고, 또는 악성코드 제작자가 언패킹을 위해 일부로 비워놓은 섹션일 가능성도 존재하기 때문에 의심스러운 섹션으로 판단한다.
그리고 이는 코드 인젝션(Code Injection)이나 프로세스 할로잉(Process Hollowing)에도 적용되는 기법이기도 하다.

두 번째는 엔트로피 값이 7 이상인 경우이다.
위에서 패킹된 파일이라면 엔트로피 값이 증가함을 설명했다.
패킹하는 것은 압축하는 것이고 압축이라는 것은 파일 내에서 자주 보이는 패턴을 특정한 작은 값으로 변환하는 원리이다.
라고 설명했다.
일반 파일은 데이터 패딩에 의해 0h값이 굉장히 많이 분포하고 이 규칙성은 엔트로피 값을 낮춘다.
패딩(압축)은 이 자주 등장하는 규칙을 특정한 작은 값으로 변환하는 것으로 패딩 된 섹션의 경우 엔트로피 값이 현저히 증가하게 된다.
이에 따라 정상적인 프로그램은 대부분 엔트로피가 4~6 수준을 유지하기 때문에 '섀넌 엔트로피(Shannon Entropy)' 공식에 기반해 엔트로피가 7 이상이면 엔트로피 값이 정상 범주를 넘어갔다고 판단하게 된다. 따라서 악성코드로 의심할 수 있는 근거(패킹된 파일)가 되기 때문에 의심스러운 섹션으로 판단한다.
하필 7이라는 숫자가 기준점이 되는 이유는 간단히 설명하면 물리적으로 가질 수 있는 완벽한 무작위성의 한계치가 8이기 때문이다.
섀넌 엔트로피 공식에 기반 해 최대 엔트로피 값은 8이다.
1바이트로 표현할 수 있는 숫자의 가짓수는 2^8 = 256개(0x00 ~ 0xFF) 이기 때문이다.
따라서 현존하는 압축 프로그램이나 암호화 알고리즘을 가져와도 완벽한 난수(8.0)를 만들어내는 것은 불가능에 가깝기 때문에 강제로 끌어올려지는 7 이상의 수치를 기준점으로 잡은 것이다.

이렇게 peframe.py 도구를 활용하여 3.3. 과 3.4. 의 두 가지 조건에 의해 sections 함수가 어떻게 의심스러운 파일, 즉 패킹된 파일을 탐지하는 지에 대해서 정리했다.
4. 마무리
악성코드 정적 분석의 첫 단추인 패킹의 간략한 개념과 엔트로피에 대해서 설명하고, peframe.py 도구를 활용하여 3.3. 과 3.4. 의 두가지 조건에 의해 sections 함수가 어떻게 의심스러운 파일, 즉 패킹된 파일을 탐지하는지(malware를 판별할 수 있는지)에 대해서 정리했다.
개인적으로 공부하면서 재미있다고 느꼈던 개념이기도 해서 정리를 시작했지만 막상 정리를 시작하니 조금 더 선행되어야 할 포스팅 주제들이 많다는 것을 느꼈다.
글 중간에 언급했던 것처럼 이번에 다루지 못한 구체적인 PE 구조(Portable Executable) 헤더 분석과 오픈소스 분석 도구인 peframe.py의 모듈별 상세 소스코드 분석은 조만간 별도로 포스팅해야겠다.